Chapter 1: AI Statelessness and Context Window
Understanding AI hinges on understanding its statelessness. Your codebase should shed all procedural and historical baggage so that any reader, every AI session, needs zero historical context to operate.

"Understanding AI hinges on understanding its statelessness. Your codebase should shed all procedural and historical baggage so that any reader, every AI session, needs zero historical context to operate."
Extended reading: How the test system provides a safety net for uncertainty in a stateless world, see Test/Code Loop: Why Test Code Is More Important Than Functional Code.
1. Understanding AI statelessness
Understanding AI hinges on understanding its statelessness. Your codebase should shed all procedural and historical baggage so that any reader, every AI session, needs zero historical context to operate.
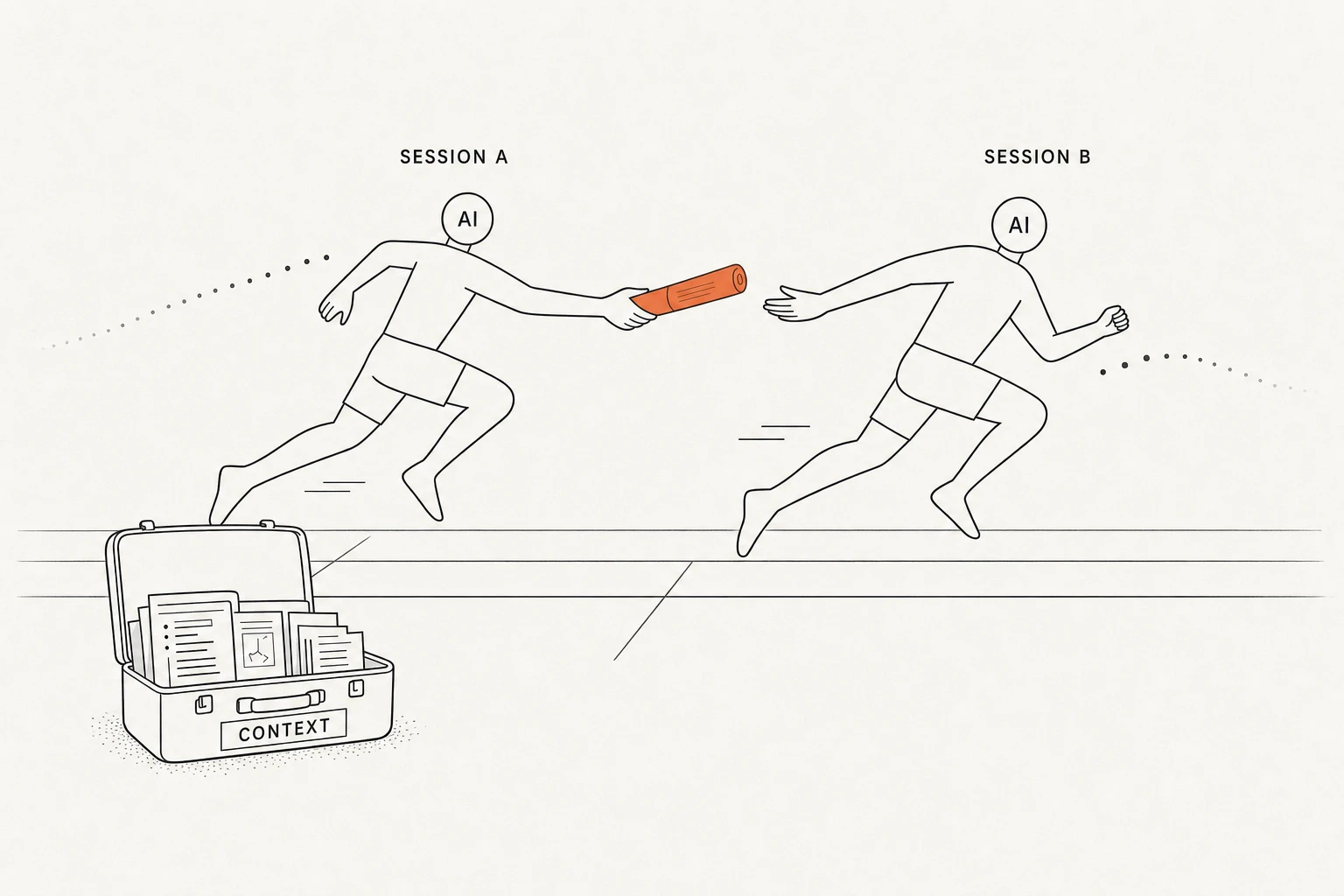
If an AI's context and capabilities have an upper bound for a single work session, we need to let AIs work in relay on the same problem. A better approach is:
- Have the previous AI session write all the context it has acquired into a document
- Start a new AI session and have it read that document, then continue working from there
Codebases cannot contain large amounts of documentation. We once tried a workflow:
- For each new requirement, have AI write a PRD first
- Then have it write a TDD technical document based on the PRD
- Then have it write an execution record based on the technical document
- Then write code based on the execution record
- When code is half-written, come back and update that execution record
We used this approach for over a dozen requirements, but eventually couldn't bear it anymore. The reason was that the documentation it produced was simply too much: human brains couldn't read through it all. If human brains can't read through it, imagine what happens to your codebase: you lose control, you don't know what AI will fill in, and you have no way to evaluate or review AI's work. It will inevitably collapse very quickly.
2. Code as documentation: why we should abandon historical information
Codebases cannot have too much documentation, because a good goal that everyone pursues is "code as documentation."
If your code is written well enough, which is actually achievable with today's AI capabilities, it can do well in naming and structural organization.
In this case, you don't need to repeat and convey the same information. Because doing so will occupy its context space, and when you occupy AI's context window, AI becomes dumber.
Documentation cannot always stay in sync with code. Especially in today's high-productivity environment with AI assistance, you can't even finish reading all the new code AI has changed each day, let alone keep documentation and code in sync.
As long as code and documentation are out of sync, every AI session will receive two contradictory pieces of information:
"As soon as AI receives contradictory information, it becomes dumber, because it doesn't know which one is correct. It will naturally assume everything you tell it is true. It will think A is correct and B is correct, but only one is correct. Once it falls into this confusion, it becomes dumber."
Therefore, the amount of documentation in the entire codebase must be kept minimal and clean, and kept in sync as much as possible. Otherwise, you're just reducing AI's capabilities.

3. Context window: the most important resource for programmers in the new era
"The upper bound of AI's context window will be the most important 'resource' for programmers in this new era."
Extended reading: How token count quantifies project scale and impacts context selection strategies, see Token as a Quantitative Measure of Project Scale. For practical tool selection based on context window constraints, see Tools and Context Selection: Why AI IDEs Sell "Context Selection Capability".
In the past, people cared about CPU, memory, and hard drives, but as time goes on, these things are getting cheaper. What's most expensive now? Tokens.
AI's performance changes based on how much context window you occupy. When you find AI's capabilities improving, you'll definitely push against its upper limit, and you'll definitely become more wasteful. Even if the model itself becomes cheaper, because your usage increases dramatically, the money you spend may still be increasing.
The principle of large model sessions is roughly this:
You originally had four messages in this session, and you want to send a fifth message. It's not actually continuing on the original session, but creating a new message whose context is the previous four messages. This means that even though it looks like the same session, there's actually no relationship between each message.
This leads to the problem of token cost management:
- If you only have two messages in a session, the tokens you consume are only the cost of two messages
- If the session already has ten messages, and you send the 11th and 12th messages, your cost isn't just two messages, but scales like 1 + 2 + … + 11
Therefore, the longer you use it, the more you use, and the more expensive it becomes.
Vendors will have a workflow behind the scenes that automatically compresses previous messages, most likely using large models: the large model reads 10,000 words of the conversation, then outputs a 1,000-word summary. As soon as messages are compressed, some information is inevitably lost, and this information might be the most critical. At the same time, large model performance itself declines as the occupied context space increases. Each large model has its own different sweet spot at different context lengths. Therefore, the longer a session, the dumber the AI becomes.
Empirically, when a session's context left is only 40%, it will already start to "become dumb." At this point, try to restart.
4. Session relay strategy in a stateless world
For requirements of medium complexity and above, a relatively healthy workflow is:
- In the first AI session, have it read as many global documents and related code as possible. After it has enough understanding of the problem background, have it write an execution plan
- Carefully review this plan, clarify every point you find unreasonable or questionable with AI, then have it solidify this document
- Start a second AI session, have this new AI read the document, then follow the document step by step
- When you find it becoming "dumb" at some step, restart a new AI and have it continue from where it was interrupted (of course, it needs to understand what we've already done first)
After the entire plan is complete, including tests, lint, and quality checks passing, delete this plan.
Because this plan contains a lot of procedural information. If a future AI session reads these procedural pieces of information, it will be misled.
A correctly maintained codebase should not contain any procedural information, only result information.
It won't say "I changed A to B," otherwise it would require new readers to understand why it was A in the past and why it's B today, creating confusion in their minds.
You should delete all information related to A and only keep B.
This way, any new reader, including every new AI session, doesn't need to try to understand "what once existed."
The complete form of this relay strategy in actual workflows, see AI-Native Workflows: Plan/Act, Test/Code, Doc/Code/Doc.
5. Full/snapshot documentation vs. incremental documentation
Documentation is essentially helping large models cache memory.
Full, snapshot-style documentation is superior to incremental documentation.
AI's capability upper bound is the upper bound of its context window. Humans are the same: human context windows also have upper bounds.
How do humans handle complex systems? Think about how large companies collaborate:
- Different functions and teams collaborate through clear boundaries and interfaces
- Each team has a complete "snapshot understanding" of its own context, rather than relying on a long development history
Our collaboration with AI is actually simulating this collaboration between different functions and teams in large companies.
How documentation and code stay in sync in this mode, and how documentation participates in workflows, see AI-Native Workflows: Plan/Act, Test/Code, Doc/Code/Doc.