第 4 章:工具与 Context 选择——为什么 AI IDE 卖的是“上下文选择能力”
AI IDE 或 AI Agent 卖的是两个:一个是 Context 选择的能力,一个是最佳实践通用化的能力。

“AI IDE 或 AI Agent 卖的是两个:一个是 Context 选择的能力,一个是最佳实践通用化的能力。”
延伸阅读:Context window 的物理边界及其对工程实践的影响,参见AI 的无状态性与 Context Window。
本章聚焦于:不同 AI Coding 工具的特性、商业模式带来的隐性约束,以及为什么 RAG、任务管理器、多 Agent 这些“看上去很聪明”的东西,在 AI-native 工程实践里,往往是反模式。
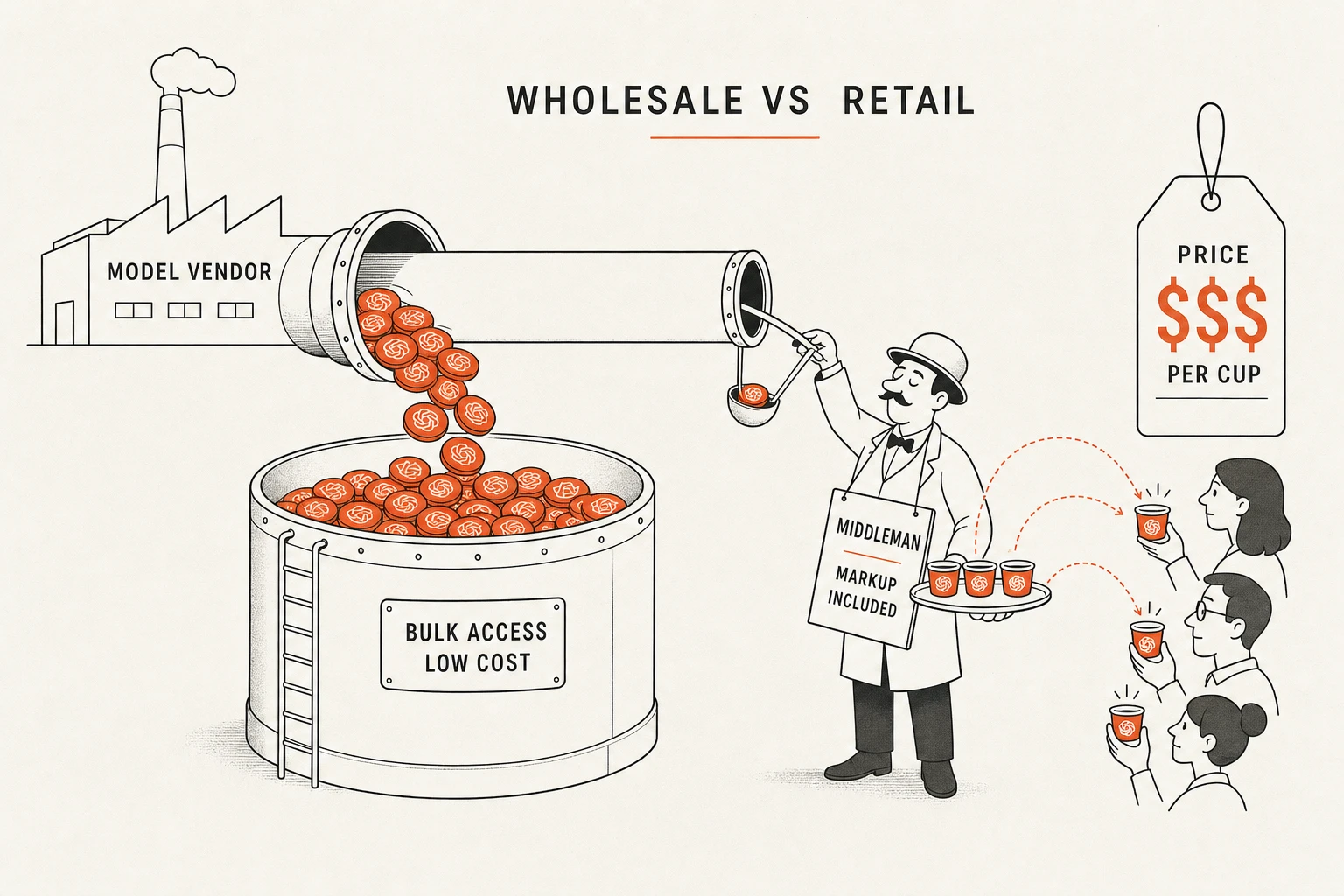
1. Cursor 的商业模式问题:批发转零售
从商业角度看,Cursor 的生意模式是“批发转零售”:
- 它从大模型厂商那里批发 token
- 再零售给个人开发者
- 为了利润最大化,它必须“降本增效”,其中最直接的手段就是:压缩你的上下文
一旦上下文被压缩:
- 压得不一定对,可能丢失非常关键的信息
- 压缩完之后,大模型缺失了必要的细节,做出的判断就会出错
- Cursor 用户量越大,它的盈利压力越大,它就越有动力在你看不到的地方,偷偷压缩上下文
结果就是:你以为它读了整个文件,其实它只看了中间的几段。
2. 最好的工具往往来自模型厂商
延伸阅读:Token 规模如何影响工具选择决策,参见Token 作为项目规模的量化指标。
因此,最好的工具其实是大模型厂商自己出的工具:
- 他们没有动力去压缩上下文
- 他们真正关心的是“获取更多数据来训练自己的模型”
- 所以不会在你看不到的地方悄悄丢信息
代价是:
— 不是所有普通人都付得起账单。随随便便聊几十刀、几百刀就下去了,20–200 美元反而成了“均价”。
3. Web 端 + 大上下文:Gemini 的用法
另一个思路是:直接用模型厂商的 Web 端界面。
比如 Gemini:
- 上下文有一百万 token
- 可以借助一些工具把整个代码库一键打包成一个文档
- 把文档贴到 Web 端,再和它讨论你的问题
但这里最大的问题不在工具,而在于:
- 你要有能力理解它给你的答案
- 你要有能力确认它改动的范围、改动的合理性
- 否则只是把“难以 review 的代码”换了一个通道涌进来
当你在 Web 端处理超大上下文时,内部仍然需要用Test–Code 循环:为什么测试代码比功能代码更重要中所强调的测试体系来兜底。
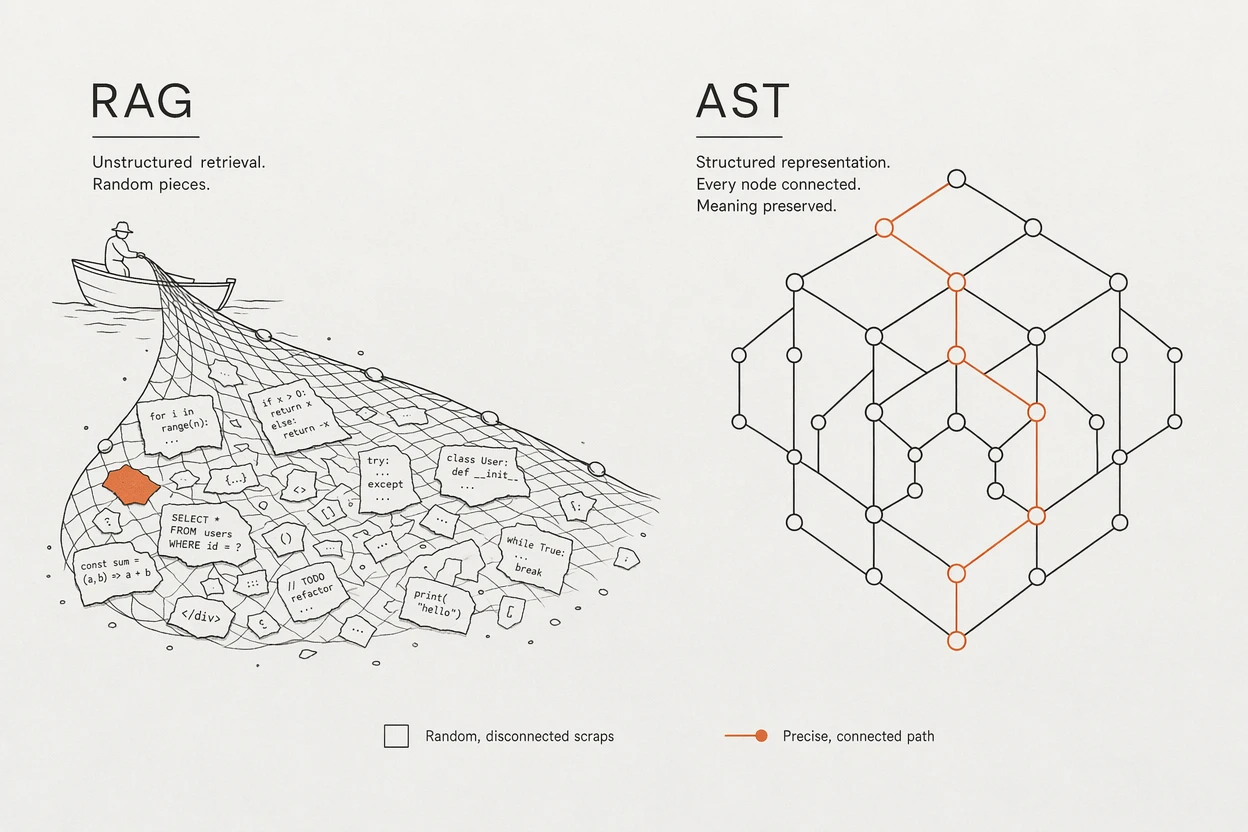
4. RAG vs AST:为什么符号索引比“聪明检索”更可靠
Cursor 找东西用的是 RAG。
RAG 这个技术从工程角度看,一个最大的缺点就是:准确率特别低。
“cursor 经常会找出来一些似是而非的东西。唯一可靠的,是对符号建立索引,也就是所谓的 AST。”
后来我们知道,像 codex 或者 cloud code,其实都是 AST/symbol 索引的思路:
- 让 AI 掌握一些底层的、确定性 100% 的工具,比如 grep
- 不让 AI 直接依赖“模糊匹配”的检索
- AI 第一次搜不到,可以调整关键字搜第二次、第三次,最终一定能搜到百分百正确的信息源
而对比之下:
- RAG 的“聪明程度”肯定比不上大模型本身
- 却要让聪明的大模型去依赖一个“比较蠢的 RAG”建出来的索引
- 这个组合从一开始就是不可靠的
正确的做法应该是:
“让大模型自己来建索引,然后让大模型调自己的索引。”
5. 多任务、多 Agent、Task Manager:直观但错误的想法
市面上有很多基于 AI 的“任务管理器”产品:
- 让你在里面写 PRD、写粗略需求
- 用一套 Plan 工具先产出非常详细的任务列表、依赖关系、验收标准
- 然后用 Execute 工具让 Agent 并发执行这些任务
- 最后自动回测结果
这条路径的出发点是好的,我自己也在这条路上走了大半年,甚至手搓过类似的 pipeline。
但最后我把这类流程全部淘汰了,原因在于:
- 它给人类造成了巨大的心智负担:PRD、Tech Doc、执行记录,一堆文档都要保持同步
- 一旦有不一致,就意味着你在给 AI 误导,它就很容易做错事
- AI 自己在每个 task 上都有一点点误差,比如 1%,多 task 并行之后,误差会几何级放大
“就算是 codex 这么强的 AI,它也做不到安全地并行开发复杂项目。错误太容易累积。”
因此,与其追求多 Agent、多流水线的“酷炫感”,不如老老实实串行地干。
6. 文档与代码的一致性:不要让 AI 吃到矛盾信息
围绕工具与 context 选择,还有一个非常关键的点:文档和代码的一致性。
很多人会有一个很自然的习惯:
想要让 AI 先写一个 plan 文档,里面有 checklist,然后让 AI 一条条勾选;
做完之后,再产出另外一份执行记录文档。
这个做法本身没问题,但问题在于:
- 这些“过程性”的 plan、执行记录,如果长期留在代码库,会和代码本身形成大量矛盾信息
- AI 读到“以前是 A,现在是 B”的描述,会搞不清楚你到底想要 A 还是 B
- 再叠加 IDE/工具自己的自动摘要、压缩逻辑,这种矛盾会被进一步放大
正确的做法是:
- Plan 文档可以写,但任务完成之后要把它删掉
- 把真正有价值的“结论性信息”抽出来,合并到主要文档里
- 不要出现“我们本来设计是 A,后来改成 B”这样的句子
这一点与AI 的无状态性与 Context Window中"删除所有 A,只保留 B"的原则是完全一致的。
7. 工具选择策略:谁干什么
结合以上所有经验,一个相对简单的工具选择策略是:
用 Codex / Cloud Code 写后端以及所有功能逻辑代码,用 Cursor 做组件开发、UI 开发、设计还原(利用 IDE 优势),需要 10^6 级别 token 上下文的场景则交给 Gemini Web 等大上下文工具。
配套的使用原则是:
- 在能力范围内,尽量直接使用模型厂商自己的工具
- 如果用 IDE 型工具,心里要非常清楚:它可能在背后帮你“悄悄省 token”
- 所有工具都只是“入口”,真正重要的是:
- 你的上下文组织方式
- 你的测试体系(见Test–Code 循环:为什么测试代码比功能代码更重要)
- 你的文档与代码是否一致(见AI-Native 工作流:Plan–Act、Test–Code、Doc–Code–Doc)
8. Context 选择是 AI IDE 的核心能力
回到最开始的那句话:
“AI IDE 或 AI Agent 卖的是两个:一个是 Context 选择的能力,一个是最佳实践通用化的能力。”
这意味着:
- 你不应该只看“提示词好不好看”“UI 漂不漂亮”
- 真正要问的是:
- 它是怎么选上下文的?
- 它会不会在背后乱压缩?
- 它是用 RAG 还是用符号索引?
- 它会不会把过程性垃圾和结论性信息混在一起塞给模型?
对于一个 AI-native 团队来说,工具选型的本质,并不是功能有多全,而是:它能不能稳定、可预期地帮你管理好上下文。