第 1 章:AI 的无状态性与 Context Window
理解 AI 的关键在于理解它的无状态性。你的代码库应该抛弃所有的过程性历史信息,让任何一个读者,也就是你的每一个 AI session 都不用去理解任何历史上下文。

“理解 AI 的关键在于理解它的无状态性。你的代码库应该抛弃所有的过程性历史信息,让任何一个读者,也就是你的每一个 AI session 都不用去理解任何历史上下文。”
延伸阅读:测试体系如何兜底无状态世界里的不确定性,参见Test–Code 循环:为什么测试代码比功能代码更重要。
1. 理解 AI 的无状态性
理解 AI 的关键在于理解它的无状态性。你的代码库应该抛弃所有的过程性历史信息,让任何一个读者,也就是你的每一个 AI session 都不用去理解任何历史上下文。
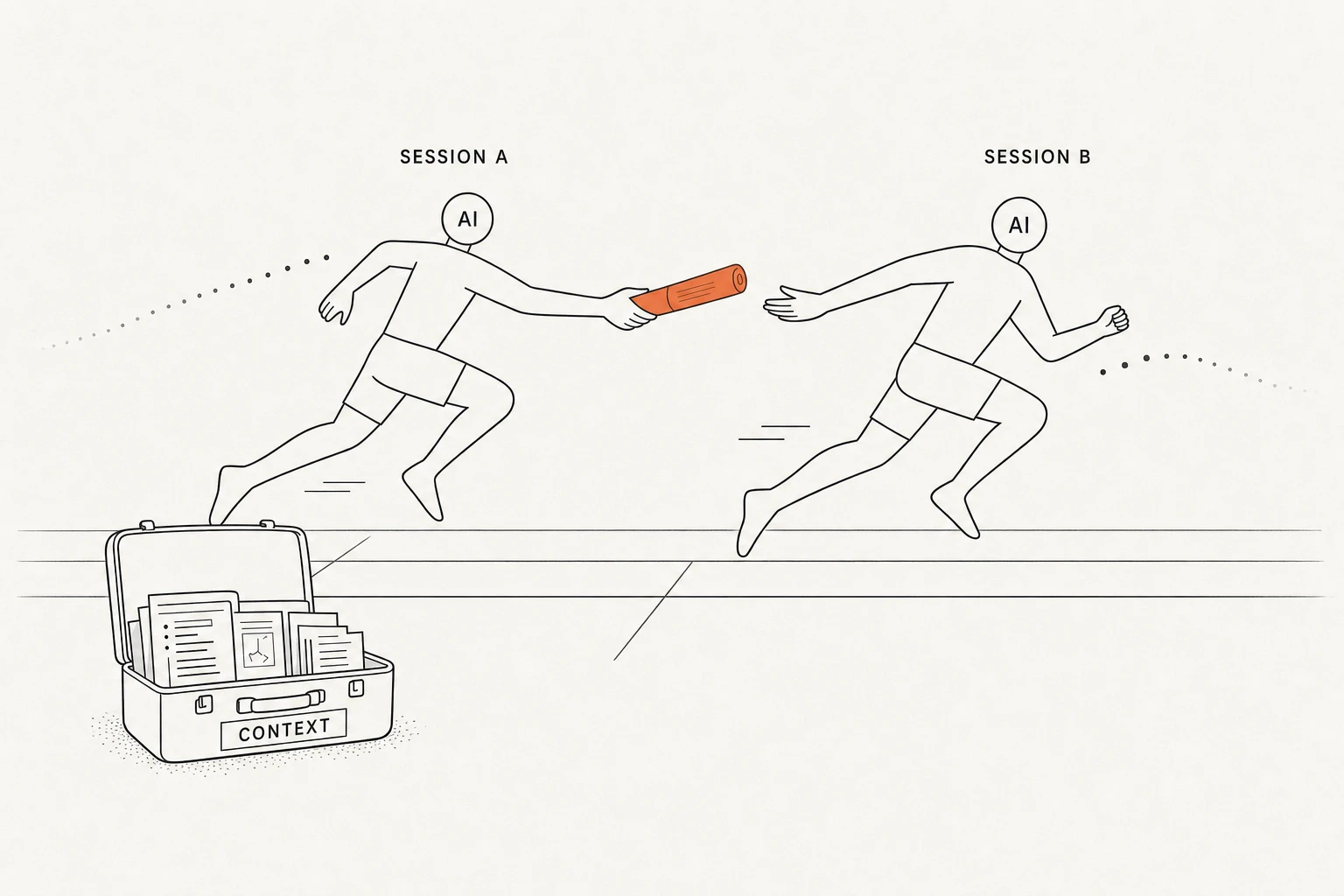
如果 AI 一次工作的 context 和能力有上限,就需要让 AI 接力在某件事情上工作。比较好的办法是:
- 让前一个 AI 会话,把它当前获取的所有上下文都写到一个文档里
- 新开一个 AI,然后让它去读那个文档,在那个文档的基础上再接着工作
代码库里面是不能出现大量的文档的。我们以前有过实践,就是我们自己尝试着编了一个工作流:
- 每次有新需求,就让 AI 先去写一个 PRD
- 然后让它对着 PRD 写一个 TDD 技术文档
- 然后再让它对着技术文档去写一个执行记录
- 然后再对着执行记录去写代码
- 代码写到一半,回来更新一下那个执行记录
这个方式,我们写了十几个需求,后来实在受不了,原因在于它产出的文档内容实在太多了,就是人脑根本就读不过来。如果人脑都读不过来的话,那你这个代码库可想而知,你自己都丧失了操控力,你也不知道 AI 会往里面填什么东西,你根本没有办法去评价、去评审 AI 的工作成果。最后一定是很快就会崩溃。
2. 代码即文档:为什么要抛弃历史性信息
代码库里是不能有太多的文档的,原因在于:一个比较好、大家都追求的目标在于“代码即文档”。
如果你的代码写得够好,这在今天的 AI 能力下其实是可以做到的——它可以在命名上、在结构区分上做到比较好。
在这种情况下,你就不需要再重复一遍,传达一模一样的信息。因为你这样会占用它的上下文空间,当你占用了 AI 的 context window 的时候,AI 就会变蠢。
文档是没有办法始终保持跟代码同步的。尤其是在我们今天 AI 帮助下产能如此高的情况下,你每天光是读 AI 新改的代码就已经读不完了,更不要说去始终保持文档和代码的同步了。
只要代码和文档不同步,每一个 AI session 它就会同时接收到两个矛盾的信息:
“只要 AI 接收到矛盾的信息,它就会变蠢,因为它不知道究竟哪一个是对的,它只会天然地认为你告诉它的东西都是真的。它会觉得 A 也是对的,B 也是对的,但只有一个是对的,它一旦陷入这种混乱就会变蠢。”
所以说整个代码库里的文档数量一定要控制得足够少、足够干净,并且尽量保持同步,否则你都是在降低这个 AI 的能力。

3. Context Window:新时代程序员最重要的资源
"AI 的 context window 的上限,将是新时代程序员最需要关心的资源。"
延伸阅读:Token 数量如何量化项目规模并影响 Context 选择策略,参见Token 作为项目规模的量化指标。基于 Context Window 约束的实用工具选择,参见工具与 Context 选择:为什么 AI IDE 卖的是"上下文选择能力"。
过去大家会关心什么 CPU、内存、硬盘,但是随着时代的发展,这些东西都越来越便宜了。现在最贵的是什么?是 token。
AI 的性能是随着你占用的 context window 的多少而变化的。当你发现 AI 能力上升的时候,你一定会顶着它的能力上限去用,一定会变得更加浪费。即使模型本身变便宜了,但是因为你的用量大增,所以你最后花的钱可能还是在增加。
现在大模型会话的原理大致是这样的:
你这个会话本来有四条消息,你要发第五条消息,它本质上不是在原来会话上继续,而是新建了一个消息,这个消息的 context 是过去的四条消息。这就意味着虽然你看起来是同一个会话,但其实每一条消息之间都是没有任何关系的。
这也就引出了 token 成本管理的问题:
- 如果你一个会话里面只有两条消息,那你消耗的 token 其实只有两条消息的成本
- 如果这个会话已经有十条消息了,你再发第 11 和第 12 条消息,你的成本就不只是两条消息,而是 1 + 2 + … + 11 这样的规模
所以说,越用到后面,用量越大,也越贵。
厂商背后会有一套工作流在自动压缩前面的消息,大概率也是用大模型去压缩:相当于大模型读了会话的一万个字,然后输出了一千个字的摘要。然后只要有消息被压缩了,就一定丢失了一些信息,这部分信息可能刚好是最关键的信息,同时大模型的性能本身就是随着占用的context空间增多而下降的,每个大模型在不同的上下文长度里,都有自己的不同的sweet spot,因此一个会话越长,AI越蠢。
经验上,当一个会话的 context left 只剩下 40% 的时候,它就已经会“变蠢”了,这个时候尽量重新开始。
4. 无状态世界里的 Session 接力策略
对于中等复杂度以上的需求,一个比较健康的工作流是这样的:
- 在第一个 AI 会话里,让它尽可能多读一些全局性的文档和相关的代码,对问题的背景有足够了解之后,让它写一个执行计划
- 认真审阅这个计划,跟 AI 搞清楚里面每一个你觉得不合理或者有疑问的点,然后让它把这个文档固化下来
- 开第二个 AI 会话,让这个新的 AI 去读这个文档,然后顺着文档一步步地做
- 当你发现它做到某一步,有点“变蠢”的时候,重开一个新的 AI,让它在打断的地方接着做(当然它需要先了解我们已经做了什么)
当整个计划完成之后,包括测试、lint、质量检查都通过了,要把这个 plan 删掉。
因为这个 plan 里面保留了很多过程性的信息。未来某一轮 AI 会话如果读到了这些过程性的信息,就会产生误导。
一个正确维护的代码库里,不应该有任何过程性的信息,它只有结果性的信息。
它不会说“我把 A 改成了 B”,否则就要求新的读者去理解过去为什么是 A、今天为什么是 B,他脑子里就会出现分歧。
你应该把所有跟 A 有关的信息都删掉,只留下 B。
这样任何一个新的读者——包括每一次新的 AI 会话——都不需要去尝试理解“曾经有个什么”。
这套接力策略在实际工作流中的完整形态,参见AI-Native 工作流:Plan–Act、Test–Code、Doc–Code–Doc。
5. 全量 / 快照式文档 vs 增量式文档
文档化,本质上是在帮大模型做记忆的 cache。
全量的、快照式的文档优于增量式的文档。
AI 的能力上限就是它的 context window 的上限,其实人类也是一样,人类的 context window 也是有上限的。
那么人类是如何 handle 复杂系统的?回想一下大厂是如何协作的:
- 不同职能、不同团队之间通过清晰的边界和接口协作
- 每个团队对自己的上下文有完整的“快照式理解”,而不是依赖一整段发展历史
我们与 AI 的协作,其实就是在模拟这种大厂里不同职能、不同团队的协作。
文档与代码如何在这种模式下保持同步,以及文档如何参与工作流,详见AI-Native 工作流:Plan–Act、Test–Code、Doc–Code–Doc。