SSOT: Why Every Software Engineering Principle Is Really About One Thing
Complex products, AI-native output, and fast iteration naturally split team truth. The SSOT Nine-Layer Pyramid lets AI agents, product, operations, sales, support, and engineering share one current decision snapshot.

SSOT: Why Every Software Engineering Principle Is Really About One Thing
Ask a new engineer, or an AI agent entering the repository for the first time, a simple question:
What is the product's core capability right now?
Will it get the same answer from the README, roadmap, tests, logs, release evidence, API names, and public messaging?
Ask the same question from another angle: when product, operations, sales, or customer support needs to answer "Can we promise this capability?", "Is this still the mainline?", or "What did this release actually prove?", can they find the answer from the same truth source?
If not, the team does not have a documentation problem. It has a truth problem.
The most important principle in software engineering is SSOT: Single Source of Truth.
Many principles look unrelated: DRY, KISS, SOLID, modularity, domain modeling, testing strategy, observability, CICD, documentation governance. They operate on different surfaces: code, architecture, tests, releases, collaboration, and organizational workflow.
But if you merge them down to their root, they all address the same question:
When a system becomes too complex for human memory, what should the team trust?
DRY is not merely "do not duplicate code." It is "do not let the same fact live in multiple competing places."
KISS is not a refusal to handle complex business logic. It is the discipline of keeping the path to truth short enough that humans and AI can still identify the authoritative source.
SOLID is not class-design ceremony. It is a way to keep responsibility boundaries stable so one module does not become the accidental owner of unrelated facts.
Domain modeling is not drawing nouns. It is preventing business concepts from being scattered across UI labels, API paths, database columns, scripts, logs, and people's memory.
Testing is not about "running more things." It is about creating executable truth for expected behavior.
Observability is not about producing more logs. It is about giving production state an inspectable source of truth.
CICD is not automation for its own sake. It is a unified truth source for whether a version can merge, release, and be trusted after release.
So SSOT is not "write one more master document." It is the meta-principle behind engineering discipline: every important fact needs one authoritative home, a clear owner, and enough evidence to prove it is still true.
Complex Systems Inevitably Split Truth
Small systems can run on memory. A few people sit together and everyone knows which endpoint is real, which page is old, which script was temporary, and which test can be ignored.
That does not scale.
The moment a business system keeps iterating, human memory starts to decay. A team might rebuild the same wheel every month, then completely forget it happened. Different team members may have solved the same problem in different places. A special design may have been created for a historical stage, while the product has since moved on, leaving old code, old tests, and old explanations behind.
Over time, the problem is not "nobody wrote documentation." The problem is that every place contains a bit of documentation, but no place owns current truth.
AI-native work makes this worse.
AI can produce architecture proposals, code, tests, logs, public copy, meeting notes, release summaries, and internal plans at a volume no traditional documentation system was designed to absorb. These artifacts are useful, but without fact ownership they quickly become noise.
At the same time, everyone is becoming a broader operator. Engineers need to understand product, design, operations, release, and commercial strategy. Product decisions must travel all the way down to implementation. Product, operations, and engineering need to stay aligned while strategy keeps changing.
In that world, the scarce resource is not more content.
The scarce resource is knowing which content counts.
This Is Not an Internal Engineering Problem
Many teams treat SSOT as "engineers should write clearer docs." That is too narrow.
For an AI agent, SSOT is an action boundary. An AI agent does not know which proposal was from three months ago, which README line was a temporary migration note, or which green test only protects a legacy path. It will place old strategy, new code, stale logs, open tasks, half-finished meeting notes, and public copy into the same reasoning space.
Without explicit fact ownership, an AI agent tends to make three dangerous mistakes:
- It treats legacy capability as the current mainline and keeps adding docs, tests, or automation around it.
- It treats a POC as a committed product capability and over-packages plans or marketing copy.
- It merges several historical "current priorities" into one confident but wrong execution plan.
That is not an intelligence failure. It is a team failing to tell the agent what to trust.
For non-engineering teammates, SSOT is the collaboration entry point. Product needs to know the current strategy. Operations needs to know which workflow can really run. Sales needs to know which capabilities can be promised. Customer support needs to know which logs, evidence, and fix path a user problem should enter.
If these answers are scattered across different documents, non-engineering teammates have to rely on verbal sync, the latest meeting, a page that looks recent, or an engineer's instant answer. That may feel fast in the moment, but over time it splits external promise from engineering reality, operations workflow from product state, and customer problems from evidence.
So SSOT is not engineering documentation hygiene. It is the shared truth system for AI agents, product, operations, sales, customer support, release operators, and engineering.
Decisions Do Not Penetrate Assets by Themselves
Teams constantly change focus. A capability stops being core. A new direction becomes important. An experiment proves it deserves more investment. An old module enters legacy status.
The decision itself is only the beginning.
After a product focus changes, documentation, code, tests, logs, API names, error copy, release notes, public messaging, and meeting notes cannot all change overnight. The system starts containing statements that were each true at some point, but no longer belong to the same product era:
- One document says A is the core capability.
- One code path is already serving B.
- One test suite still protects old A.
- One release checklist starts validating B.
- One marketing page still sells A.
- One AI agent reads an old note and continues working as if A is still the mainline.
This is the real chaos in complex systems. The team may have made a decision, but the decision has not penetrated all product, operations, and engineering assets.
Explicit repositioning is the easy case. If the team declares "the core product moves from A to B," everyone at least knows a migration is happening.
The harder case is gradual change. A small POC slowly becomes the strategic core. A strategic core slowly decays into legacy technical debt. During that transition, every asset can live on a different slice of time. One file treats the capability as critical. Another treats it as experimental. Another assumes it is already irrelevant.
Without SSOT, the team cannot decide which conflict should win.
Without a layered model, the team cannot inventory the impact surface of a decision.
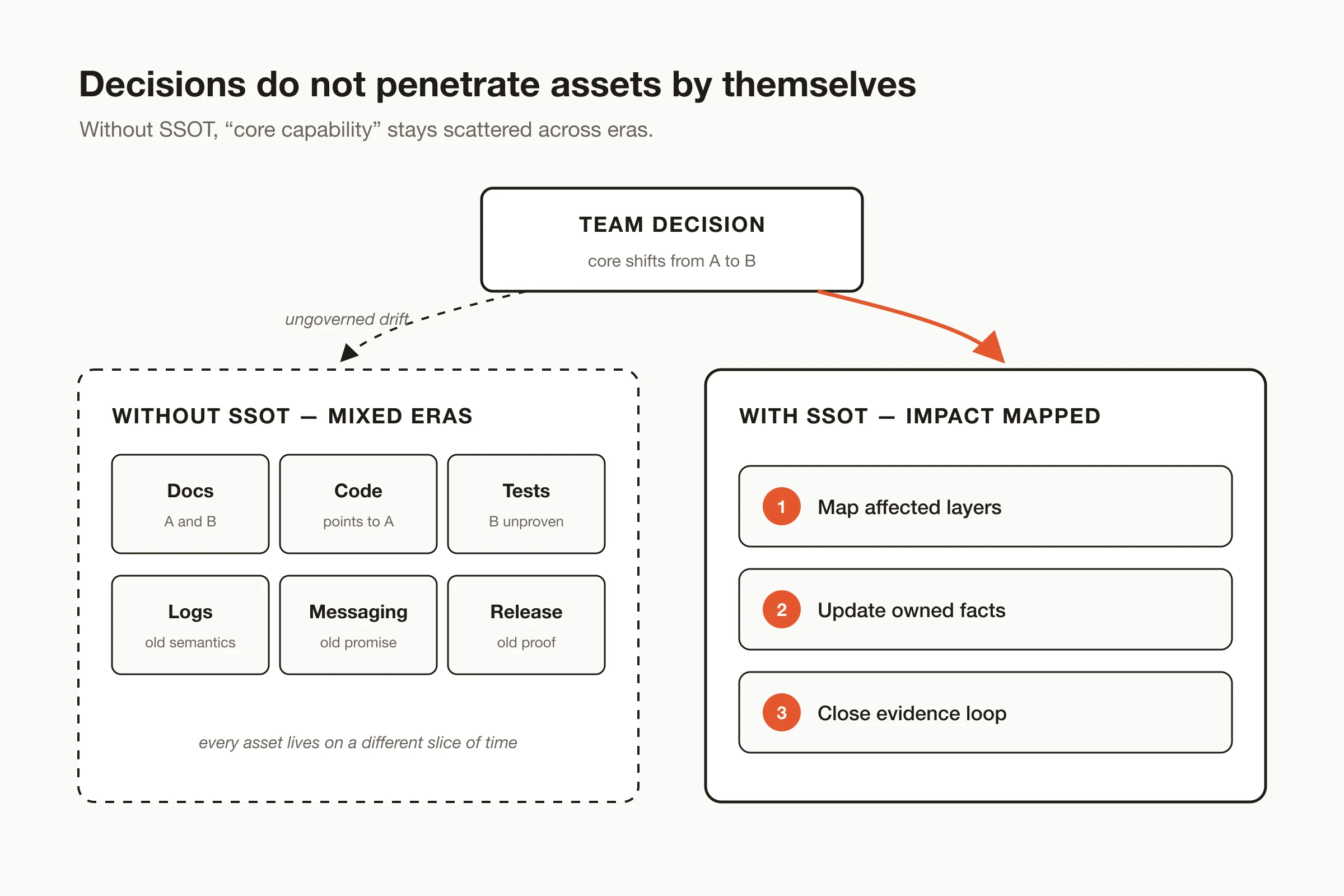
Figure: without SSOT, the phrase "core product capability" remains scattered across different historical layers of docs, code, tests, logs, and messaging.
"Current Priority" Is a Common Source of Split-Brain
One of the most dangerous forms of truth drift is also one of the most ordinary: every document says "current priority," "current focus," or "next-stage direction."
The README says it once. The architecture doc says it again. A design proposal says it again. A meeting note says it again. A release summary says it again.
Each sentence may have been true when written. Then the business, product, and engineering context changes.
For humans, this creates reading debt. When you see "current priority," you do not know whether it is still current.
For AI, it is worse. AI treats every authoritative-looking sentence as context. If five documents all describe "the current priority," and only one is still true, the model may synthesize a confident but wrong answer.
That is split-brain.
The answer is not to ban direction-setting language everywhere. The answer is fact ownership. Current priority, owner, and resource contention need one SSOT. Other documents can link to it and explain the stable structure they serve, but they cannot duplicate the current-state claim.
Otherwise, every sentence containing "current" becomes a future trap.
Why the SSOT Nine-Layer Pyramid Exists
The SSOT Nine-Layer Pyramid does not exist to make documentation heavier. It exists to force every human and AI reader to understand the system through the same path.
When reading, the pyramid forces a top-down route: mission, strategy, promise, Flow, domain model, system boundary, contract, implementation, evidence. You cannot jump into code and use one historical implementation to define today's product direction.
When producing, the pyramid forces a bottom-up route: implementation and evidence first, then contract, boundary, domain model, Flow, promise, strategy, and mission only when the lower-layer change truly alters upper-layer meaning.
The pyramid is always trying to be the most up-to-date team snapshot: a current map of business, product, and engineering decisions.
It also forces priority ranking for every concept that enters the team's thinking:
- Is it only a script?
- Is it a POC?
- Is it a candidate capability?
- Is it an internal workflow?
- Is it a user-facing promise?
- Is it current strategy?
- Is it part of the team mission?
- Has it already become legacy?
Until that question is answered, code, documentation, tests, releases, and public messaging will drift.

How the Pyramid Helps Each Role
The Nine-Layer Pyramid does not ask everyone to become an architect. It does the opposite: it gives each role a clear entry point so they do not have to read the whole repository or guess which artifact wins.
| Role | Common Trap | How the Pyramid Helps |
|---|---|---|
| AI agent | Treating every readable artifact as equally authoritative context | Read mission, strategy, promise, and Flow first; then inspect contract, implementation, and evidence |
| Product | Treating a historical proposal as current product direction | Use L1-L3 to confirm long-term identity, current strategy, and promise boundary |
| Operations | Knowing that something must run, but not which workflow owns it | Use L4 Flow to confirm the user, AI agent, release operator, support, and engineering path |
| Sales and marketing | Turning a candidate capability, POC, or internal workflow into a public promise | Use L3 Promise to decide what can enter website copy, pitch decks, demos, and sales narrative |
| Customer support | Routing user problems by experience without evidence | Use L4 Flow and L9 Evidence to find logs, state, release evidence, and responsibility boundary |
| Engineering | Changing code without knowing whether upper-layer meaning changed | Update implementation and evidence first, then promote changes through contract, boundary, domain, Flow, promise, and strategy only when needed |
For AI agents, the pyramid should behave like a boot sequence. No task should start from a random nearby file. The agent must first confirm current mission and strategy, then promise and Flow, and only then move into code, scripts, tests, and logs.
For non-engineering teammates, the pyramid is a business map. They do not need to read every contract or source file, but they must be able to find current strategy, dependable capability, real workflow, and evidence. Whenever they write public copy, customer replies, operating procedures, pitch decks, or release notes, they should reference the owning SSOT instead of copying a new "current focus" statement.
For engineering, the pyramid is the reverse update rule. Any implementation change needs evidence first. Then the team decides whether it changes contract, boundary, domain model, Flow, promise, or strategy. That is how business decisions reach code without code silently redefining business truth.
Concrete Scenarios: How Truth Actually Splits
Scenario 1: An AI agent reads an old truth
The team has decided to move the product core from an "AI skills catalog" to creative video generation workflow. But an old README still says "the current core capability is the public skill catalog," and an old test still validates the skill-list page.
An AI agent receives a task: "fill the test and documentation gaps for the current core capability." Without SSOT, it may follow the old README, add skill documentation, improve skill tests, polish the skill page, and even write a summary saying skill catalog is the mainline.
Each step looks reasonable. The overall direction is wrong. The agent is not advancing the current product; it is reinforcing the previous product shape.
The pyramid's fix is that the agent must read L1-L4 first: mission, strategy, promise, and real Flow. Only then should it inspect L5-L9: domain model, boundary, contract, implementation, and evidence. Old README files and old tests may exist, but they cannot override the upper-layer SSOT for today's product core.

Scenario 2: A POC becomes an external promise
A POC demo page is still online. It can run one automated creative-video chain. Sales sees it and writes "automated creative video generation workflow is supported" into a pitch deck. Operations sees a green release check and schedules a customer trial. Customer support investigates failures through old skill logs.
Then the team discovers the demo working once did not make the product promise true. There is no stable contract, no release evidence, and no clear recovery path. The breakage is not one skill; it may be workflow state transition, artifact ownership, or provider permission.
SSOT does not prevent non-engineering teammates from sharing progress. It defines what may be shared as promise. Only capabilities that enter L3 Promise and are backed by L9 Evidence should appear on the website, in pitch decks, in demos, or in customer commitments.
Scenario 3: Naming drift pulls engineering back into the old world
Early code is full of skillTask, skillRun, and skillResult. Later, the product core becomes workflow, but code, database fields, logs, and documents still use skill as the central concept.
New engineers and AI agents naturally infer that skill is still the domain center. New work keeps adding skillTask. Debugging keeps searching for skill failed. Design docs keep modeling around skills.
This is not a naming-style issue. Names are facts. When meaning moves from skill to workflow, symbols, domain model, contracts, logs, and tests must move too. Otherwise old names keep pulling the team into the old product model.
Scenario 4: An internal API silently becomes a public contract
An endpoint starts as a POC-only internal API for submitting video generation tasks from one script. Later, frontend, CLI, AI agents, and release scripts all begin calling it. But the contract document is never promoted, and tests still cover only the first script path.
One day an engineer renames a field, believing it is an internal refactor. CLI breaks. Agent calls fail. Release scripts cannot receive state. Customer support cannot find the matching evidence.
The problem is not that interfaces can never change. The problem is that the endpoint has already moved from L8 Implementation to L7 Contract. Once several entry points depend on it, it needs a contract, caller inventory, change rule, and evidence.
Scenario 5: Test entry points multiply until nobody knows what to trust
Many repositories slowly accumulate commands: test, test:e2e, test:smoke, test:release, check, verify, ci. Every command had a reason when it was created. Years later, nobody knows which one proves release readiness.
Engineers run the command they remember. AI agents choose the command whose name looks relevant. CICD may run the historically easiest set of checks. Everyone can say "I ran tests," but nobody can say "this check proves the current promise."
Test entry points need SSOT too. Each entry point must state what fact it proves, when it runs, who owns failures, and whether it supports a public promise. Otherwise more tests create less reliable release judgment.
Scenario 6: Green tests and stale logs create a release incident together
Old tests still protect "user opens a page and clicks generate." The new mainline depends on "AI agent reads a workflow, selects AI skills, calls a provider, writes back assets, and produces release evidence." The old tests are green, but the new path breaks at provider permission or asset state.
Worse, logs still say skill failed, and the user-facing error still says "generation failed." Engineering searches around skills. Customer support follows the old troubleshooting path. The AI agent classifies the incident as a single-skill failure.
The real problem may be workflow state machine blockage, artifact ownership, or provider permission not matching the release environment. In other words: green tests prove the old mainline, stale logs describe the old concept, and the incident happens in the new Flow.
This is why evidence must move with product focus, and logs and error copy must move with the domain model.
creative video generation workflow: From POC to Core Domain Concept
A concrete example in PostPlus.io is the elevation of creative video generation workflow.
At first, a workflow may be only a small script: several AI skills wired together to see whether a creative video production chain can run. At that stage, its impact surface is small. It needs a script, a short note, and a little evidence. It belongs mostly to implementation and evidence.
If that script keeps being used in real work, it stops being only a script. It becomes an internal capability. The team now cares about input, output, approval, failure recovery, cost confirmation, artifact location, and ownership.
At that point, it affects Flow, contract, and evidence.
If the team then discovers that "assembling AI skills into workflow" is the product's real core, creative video generation workflow becomes a first-class domain concept. It is no longer a note attached to one skill. AI skills are atomic capabilities; workflow is the structure that organizes those capabilities into real business delivery.
The impact surface keeps expanding:
- The domain model must treat workflow as a stable concept.
- The Flow layer must describe how users, AI agents, editors, operators, and developers collaborate around workflow.
- The contract layer must define inputs, nodes, approval, state, artifacts, and failure semantics.
- The implementation layer must provide data structures, scripts, pages, runners, and state management.
- The evidence layer must prove that a workflow can move from input to delivery, not just that one skill can run.
- The promise layer must decide which workflows are public commitments and which are internal candidates.
- The strategy layer must decide whether workflow is the current resource priority.
- The mission layer may even define the long-term product identity around AI agents completing real marketing work inside controlled workflows.
If creative video generation workflow becomes part of the team mission, it is no longer only an engineering concept. Public positioning, pitch decks, product demos, sales narrative, customer onboarding, and release notes should all describe it.
That is the value of the pyramid. It lets the team see which layer a concept currently occupies, and what must change when it rises.
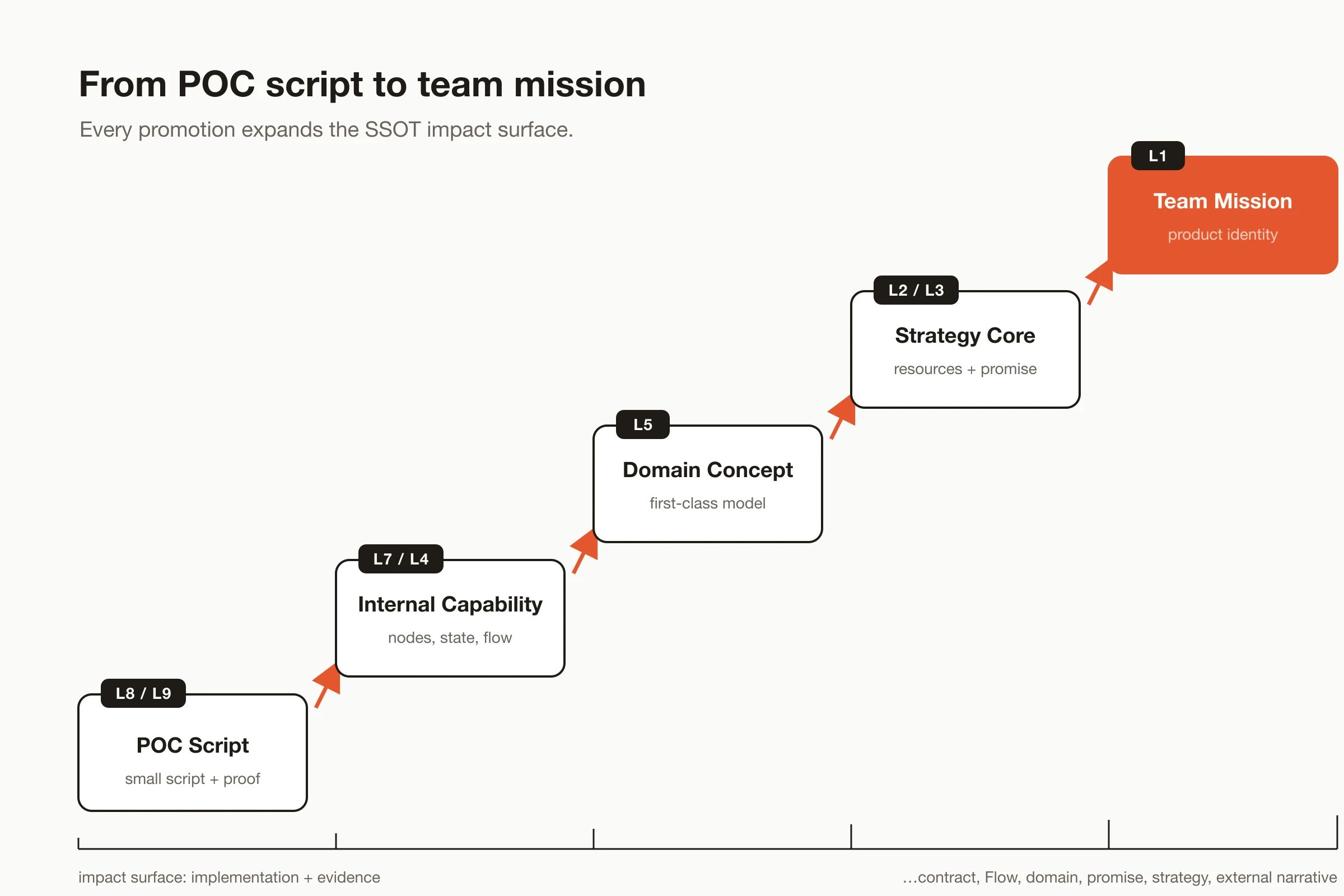
Figure: as creative video generation workflow rises from POC script to mission-level identity, its impact grows from implementation and evidence into Flow, contract, domain model, promise, strategy, and external narrative.
| Stage | Current Identity | Main Impact Surface | If SSOT Does Not Move |
|---|---|---|---|
| POC | Small script | Implementation, narrow evidence | It may be oversold as product capability |
| Internal capability | Repeatedly used in real tasks | Flow, contract, cost, approval, artifact state | Collaboration depends on oral memory |
| First-class domain concept | Business structure above AI skills | Domain model, boundary, test system | Architecture keeps treating it as a script |
| Strategic core | Current resource priority | Promise, release, roadmap, ownership | Tests and releases still protect legacy |
| Mission component | Long-term product identity | Pitch, website, sales, onboarding | Public narrative describes the wrong product |
What the Nine Layers Are
The SSOT Nine-Layer Pyramid separates a product into nine kinds of truth:
- Mission: why does the product exist?
- Strategy: what must the team win in the current stage?
- Promise: what is supported and dependable for users and the team?
- Flow: how do all stakeholders complete real tasks?
- Domain model: what are the stable concepts, states, permissions, billing rules, and invariants?
- System boundary: how do entry points, capabilities, runtime, cloud product surface, and providers divide responsibility?
- Contract: what are the executable contracts across APIs, database, environment variables, permissions, and release process?
- Implementation: how do code, scripts, migrations, components, automation, and config realize the system?
- Evidence: what tests, logs, checks, release evidence, and production facts prove the previous eight layers?
The most underestimated layer is Flow.
Flow is not a UI screen list. It is not only a user journey. It should include every stakeholder workflow around the product:
- Users entering the product, authorizing capabilities, using them, and reviewing results.
- AI agents understanding tasks, selecting AI skills, checking permissions, executing capabilities, producing artifacts, and recording evidence.
- Product, operations, and engineering turning a need into judgment, implementation, validation, and release.
- Operators running releases, observing state, resolving blockers, and collecting release evidence.
- Developers adding capability, changing contracts, adding tests, and avoiding accidental promise expansion.
- Customer support moving from user problem to logs, state, evidence, and fix path.
- Internal experiments moving from POC to candidate capability, then being promoted, paused, or deleted.
For AI-native products, this is critical. An AI agent is not a traditional UI user. It reads documents, calls tools, chooses paths, writes code, and produces evidence. If Flow does not describe the agent workflow clearly, the agent starts guessing. Once the agent guesses, SSOT begins to fail.
Flow is just as important for non-engineering teammates. Product, operations, sales, and customer support usually do not understand the system by reading component calls. They understand it by asking who does what, in which scenario, what happens on failure, and where the evidence lives. Flow puts those questions into the same model instead of leaving them to oral explanation.
That makes Flow the pyramid's organizational collaboration map: user flow, AI agent flow, product-operations-engineering flow, release flow, customer support flow, and internal experiment flow all belong in one fact system.
PostPlus.io as an Example
In PostPlus.io, the highest-level truth is not "we have a CLI," nor "we have a web app and desktop app." The more stable mission is to build an AI-facing marketing product where agents can complete real, verifiable, billable, releasable, and supportable marketing workflows.
At the strategy layer, the choices become more specific: CLI is the current control and release surface; AI skills are the capability language visible to users and agents; cloud capability, team entitlement, billing, workspace boundary, provider boundary, and release evidence are the product foundation that must be connected.
At the promise layer, "code exists in the repository" is not enough. A capability becomes a public promise only after it enters AI skills, passes real acceptance, and has corresponding evidence. Candidate capabilities, paused capabilities, and internal scripts cannot be packaged as dependable user-facing capability.
At the Flow layer, PostPlus.io does not only describe where a user clicks. It describes how AI agents select AI skills, how developers add capability, how release operators ship, how customer support investigates, how release sessions collect evidence, and how internal POCs enter or exit candidate status.
At the boundary layer, CLI, web, and desktop are entry points. AI skills express user-visible capability. AI runtime handles task understanding and orchestration. The cloud product surface owns account, workspace, entitlement, billing, tasks, and assets. External services own payment, generation, collection, publishing, and other external facts.
At the evidence layer, documentation is not evidence. Tests, status commands, release checklists, approvals, production checks, and post-release evidence are evidence.
That is what the pyramid does: every "who should we trust?" question in a complex product returns to a defined position.
Test-System Evolution as an SSOT Case
Testing is the clearest example because test systems decay when product focus moves.
Early on, a team often builds a difficult, expensive test system around the product shape that mattered at the time. It is valuable then: it covers the pages, APIs, workflows, and user paths that were the mainline.
Then decisions evolve. The product core moves. The old product shape enters legacy. The original test system becomes misaligned.
It may still run. It may still be expensive. It may even stay green.
But it proves yesterday's mainline.
It consumes maintenance cost while failing to cover today's riskiest path.
It lets the team believe "we have tests" while the new product mainline has not been proven.
The root problem is not that the team has no strategy. The problem is that evolving decisions have not penetrated all product, operations, and engineering work. A document may already say the new direction matters, while code remains organized around the old shape. Release flow may start shipping the new capability, while tests still protect old pages. Logs and error copy may still use old concepts. An AI agent may read old instructions and continue treating legacy as the mainline.
So a release can look safe: CICD is green, repository health checks are green, legacy E2E tests are green. But the capability being released has no evidence across installation path, AI skills, cloud capability, runtime contract, provider permission, billing, or release proof.
From the AI agent's perspective, this false safety is especially dangerous. The agent may treat old green tests as proof that the current mainline is covered, then keep improving automation, docs, or release notes around the old entry point. It is not intentionally ignoring the new mainline; the evidence layer did not tell it whether that evidence proves legacy or the current promise.
From the non-engineering side, the same failure is very practical. Operations sees a green release check and assumes the new workflow can run. Sales sees demo copy and release notes and assumes the capability can be promised. Customer support receives a user problem and follows old logs and old process. The incident looks like "release did not catch the issue," but the root cause is that the test system did not move with product focus.
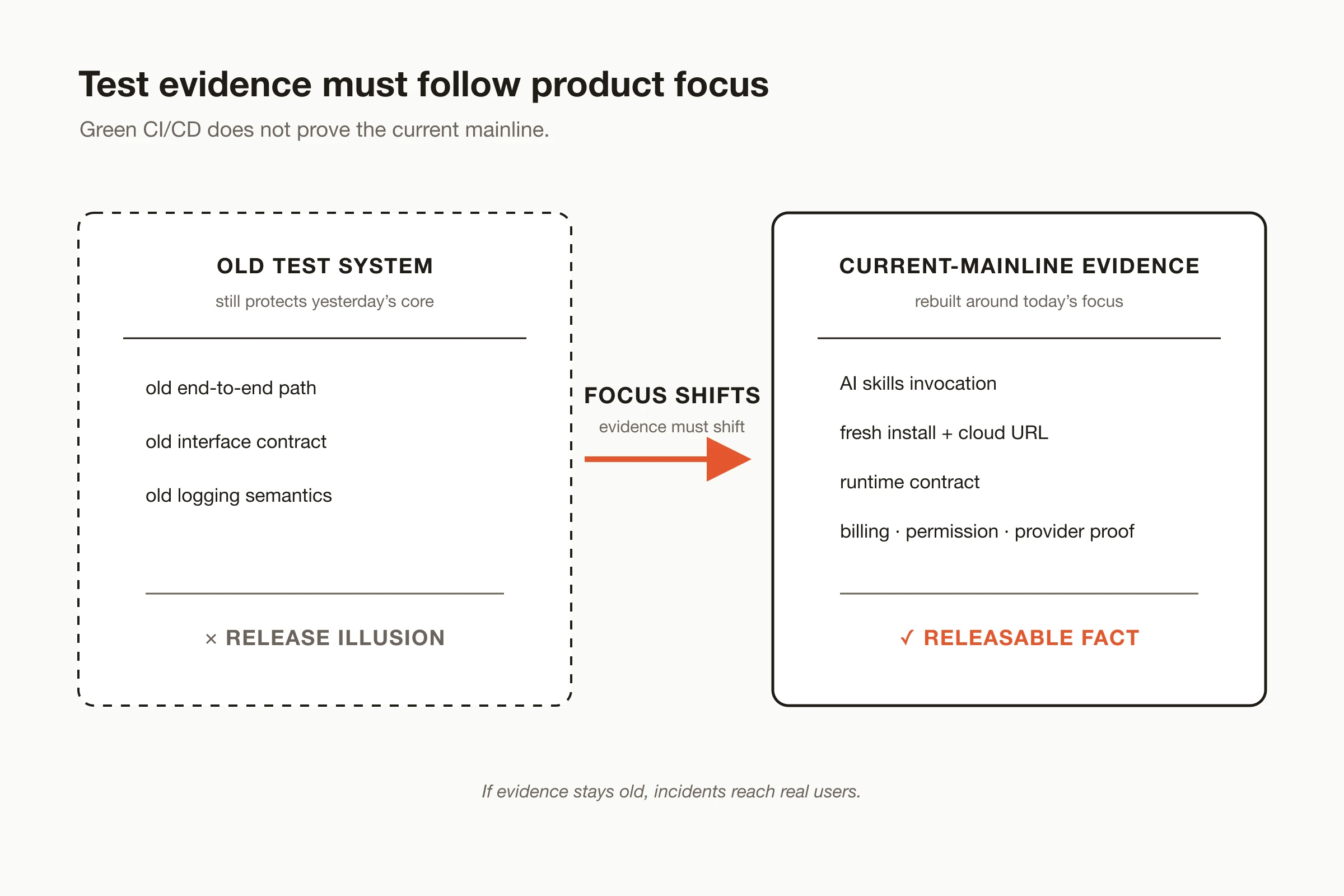
Figure: a mature test system is not simply bigger. Its evidence must move with product focus.
For PostPlus.io, test-system evolution is converging on this question:
What current product fact does this check prove?
That changes how test work is organized:
- Repository health checks prove code, types, formatting, and baseline contracts.
- Local browser journeys prove real product paths.
- AI skills checks prove the capability surface seen by agents has not drifted.
- Release evidence proves candidate version, fresh installation path, cloud URL, runtime contract, and provider path are real.
- Human experience review remains product judgment; it is not disguised as ordinary automation.
- Provider sampling has cost and permission boundaries; it does not belong in default CICD as if it were stable.
Test entry points also need SSOT. Adding, deleting, or renaming a test entry should update the test-system document before root commands, automation, or release flows change.
That is what SSOT looks like inside testing.
Next: Building Your Own Pyramid
This article explains why software engineering principles collapse into SSOT, and why complex teams need the Nine-Layer Pyramid to preserve a unified truth model.
The reusable construction method is in the companion article:
That article is not tied to PostPlus.io. It gives the root objective, layer definitions, reading rules, updating rules, document-family governance, evidence rules, and a minimal adoption checklist.
Conclusion
Complex systems always exceed human memory. AI-native production, fast iteration, full-stack collaboration, and product-operations-engineering alignment only make truth grow faster.
The core engineering problem is not how to write more code or generate more documents. It is how to keep facts from splitting.
SSOT solves that problem. The SSOT Nine-Layer Pyramid applies it to the whole product engineering system: it forces every reader to move top-down from mission to implementation, and every producer to move bottom-up from implementation and evidence back toward higher-level truth only when meaning really changes.
It is especially useful for modern software's most common transitions: a small POC becoming strategic core, and a strategic core becoming legacy debt. Every promotion needs evidence. Every demotion must narrow promise, boundary, Flow, and entry points.
When a team does this, many other principles become natural consequences: less duplication, less stale documentation, more meaningful tests, more traceable releases, and better alignment when strategy changes.
That is why I believe all software engineering principles, merged to their root, are about one thing: SSOT.